
【導(dǎo)讀】在人際交往中,言語是最自然并且最直接的方式之一。隨著技術(shù)的進步,越來越多的人們也期望計算機能夠具備與人進行言語溝通的能力,因此,語音識別這一技術(shù)也越來越受到關(guān)注。尤其,隨著深度學(xué)習(xí)技術(shù)應(yīng)用在語音識別技術(shù)中,使得語音識別的性能得到了顯著提升,也使得語音識別技術(shù)的普及成為了現(xiàn)實。

語音識別技術(shù)
自動語音識別技術(shù),簡單來說其實就是利用計算機將語音信號自動轉(zhuǎn)換為文本的一項技術(shù)。這項技術(shù)同時也是機器理解人類言語的第一個也是很重要的一個過程。
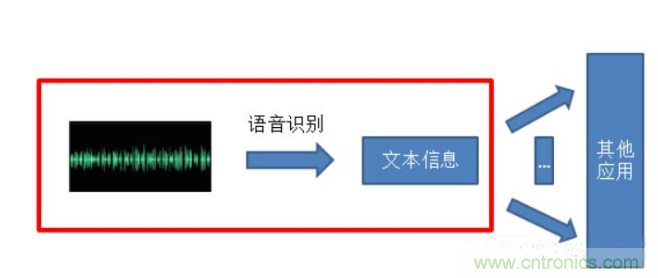
語音識別是一門交叉學(xué)科,所涉及的領(lǐng)域有信號處理、模式識別、概率論和信息論、發(fā)聲機理和聽覺機理、人工智能等等,甚至還涉及到人的體態(tài)語言(如人民在說話時的表情手勢等行為動作可幫助對方理解)。其應(yīng)用領(lǐng)域也非常廣,例如相對于鍵盤輸入方法的語音輸入系統(tǒng)、可用于工業(yè)控制的語音控制系統(tǒng)及服務(wù)領(lǐng)域的智能對話查詢系統(tǒng),在信息高度化的今天,語音識別技術(shù)及其應(yīng)用已成為信息社會不可或缺的重要組成部分。
語音識別技術(shù)的發(fā)展歷史
語音識別技術(shù)的研究開始二十世紀(jì)50年代。1952年,AT&Tbell實驗室的Davis等人成功研制出了世界上第一個能識別十個英文數(shù)字發(fā)音的實驗系統(tǒng):Audry系統(tǒng)。
60年代計算機的應(yīng)用推動了語音識別技術(shù)的發(fā)展,提出兩大重要研究成果:動態(tài)規(guī)劃(Dynamic Planning, DP)和線性預(yù)測分析(Linear Predict, LP),其中后者較好的解決了語音信號產(chǎn)生模型的問題,對語音識別技術(shù)的發(fā)展產(chǎn)生了深遠(yuǎn)影響。
70年代,語音識別領(lǐng)域取得突破性進展。線性預(yù)測編碼技術(shù)(Linear Predict Coding, LPC)被Itakura成功應(yīng)用于語音識別;Sakoe和Chiba將動態(tài)規(guī)劃的思想應(yīng)用到語音識別并提出動態(tài)時間規(guī)整算法,有效的解決了語音信號的特征提取和不等長語音匹配問題;同時提出了矢量量化(VQ)和隱馬爾可夫模型(HMM)理論。在同一時期,統(tǒng)計方法開始被用來解決語音識別的關(guān)鍵問題,這為接下來的非特定人大詞匯量連續(xù)語音識別技術(shù)走向成熟奠定了重要的基礎(chǔ)。
80年代,連續(xù)語音識別成為語音識別的研究重點之一。Meyers和Rabiner研究出多級動態(tài)規(guī)劃語音識別算法(Level Building,LB)這一連續(xù)語音識別算法。80年代另一個重要的發(fā)展是概率統(tǒng)計方法成為語音識別研究方法的主流,其顯著特征是HMM模型在語音識別中的成功應(yīng)用。1988年,美國卡內(nèi)基-梅隆大學(xué)(CMU)用VQ/HMM方法實現(xiàn)了997詞的非特定人連續(xù)語音識別系統(tǒng)SPHINX。在這一時期,人工神經(jīng)網(wǎng)絡(luò)在語音識別中也得到成功應(yīng)用。
進入90年代后,隨著多媒體時代的來臨,迫切要求語音識別系統(tǒng)從實驗走向?qū)嵱?,許多發(fā)達(dá)國家如美國、日本、韓國以及IBM、Apple、AT&T、NTT等著名公司都為語音識別系統(tǒng)實用化的開發(fā)研究投以巨資。最具代表性的是IBM的ViaVoice和Dragon公司的Dragon Dectate系統(tǒng)。這些系統(tǒng)具有說話人自適應(yīng)能力,新用戶不需要對全部詞匯進行訓(xùn)練便可在使用中不斷提高識別率。
當(dāng)前,美國在非特定人大詞匯表連續(xù)語音隱馬爾可夫模型識別方面起主導(dǎo)作用,而日本則在大詞匯表連續(xù)語音神經(jīng)網(wǎng)絡(luò)識別、模擬人工智能進行語音后處理方面處于主導(dǎo)地位。
我國在七十年代末就開始了語音技術(shù)的研究,但在很長一段時間內(nèi),都處于緩慢發(fā)展的階段。直到八十年代后期,國內(nèi)許多單位紛紛投入到這項研究工作中去,其中有中科院聲學(xué)所,自動化所,清華大學(xué),四川大學(xué)和西北工業(yè)大學(xué)等科研機構(gòu)和高等院校,大多數(shù)研究者致力于語音識別的基礎(chǔ)理論研究工作、模型及算法的研究和改進。但由于起步晚、基礎(chǔ)薄弱,計算機水平不發(fā)達(dá),導(dǎo)致在整個八十年代,我國在語音識別研究方面并沒有形成自己的特色,更沒有取得顯著的成果和開發(fā)出大型性能優(yōu)良的實驗系統(tǒng)。
但進入九十年代后,我國語音識別研究的步伐就逐漸緊追國際先進水平了,在“八五”、“九五”國家科技攻關(guān)計劃、國家自然科學(xué)基金、國家863計劃的支持下,我國在中文語音技術(shù)的基礎(chǔ)研究方面也取得了一系列成果。
在語音合成技術(shù)方面,中國科大訊飛公司已具有國際上最領(lǐng)先的核心技術(shù);中科院聲學(xué)所也在長期積累的基礎(chǔ)上,研究開發(fā)出頗具特色的產(chǎn)品:在語音識別技術(shù)方面,中科院自動化所具有相當(dāng)?shù)募夹g(shù)優(yōu)勢:社科院語言所在漢語言學(xué)及實驗語言科學(xué)方面同樣具有深厚的積累。但是,這些成果并沒有得到很好的應(yīng)用,沒有轉(zhuǎn)化成產(chǎn)業(yè);相反,中文語音技術(shù)在技術(shù)、人才、市場等方面正面臨著來自國際競爭環(huán)境中越來越嚴(yán)峻的挑戰(zhàn)和壓力。
語音識別系統(tǒng)的結(jié)構(gòu)
主要包括語音信號的采樣和預(yù)處理部分、特征參數(shù)提取部分、語音識別核心部分以及語音識別后處理部分,圖中給出了語音識別系統(tǒng)的基本結(jié)構(gòu)。
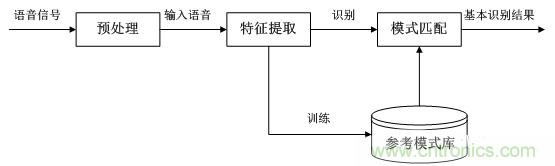
語音識別的過程是一個模式識別匹配的過程。在這個過程中,首先要根據(jù)人的語音特點建立語音模型,對輸入的語音信號進行分析,并抽取所需的特征,在此基礎(chǔ)上建立語音識別所需的模式。而在識別過程中要根據(jù)語音識別的整體模型,將輸入的語音信號的特征與已經(jīng)存在的語音模式進行比較,根據(jù)一定的搜索和匹配策略,找出一系列最優(yōu)的與輸入的語音相匹配的模式。然后,根據(jù)此模式號的定義,通過查表就可以給出計算機的識別結(jié)果。
語音識別系統(tǒng)的分類
根據(jù)識別的對象不同,語音識別任務(wù)大體可分為三類,即孤立詞識別(isolated word recognition),關(guān)鍵詞識別(或稱關(guān)鍵詞檢出,keyword spotting)和連續(xù)語音識別。
孤立詞識別的任務(wù)是識別事先已知的孤立的詞,如“開機”、“關(guān)機”等;連續(xù)語音識別的任務(wù)則是識別任意的連續(xù)語音,如一個句子或一段話;連續(xù)語音流中的關(guān)鍵詞檢測針對的是連續(xù)語音,但它并不識別全部文字,而只是檢測已知的若干關(guān)鍵詞在何處出現(xiàn),如在一段話中檢測“計算機”、“世界”這兩個詞。
根據(jù)針對的發(fā)音人,可以把語音識別技術(shù)分為特定人語音識別和非特定人語音識別,前者只能識別一個或幾個人的語音,而后者則可以被任何人使用。顯然,非特定人語音識別系統(tǒng)更符合實際需要,但它要比針對特定人的識別困難得多。
另外,根據(jù)語音設(shè)備和通道,可以分為桌面(PC)語音識別、電話語音識別和嵌入式設(shè)備(手機、PDA等)語音識別。不同的采集通道會使人的發(fā)音的聲學(xué)特性發(fā)生變形,因此需要構(gòu)造各自的識別系統(tǒng)。
目前具有代表性的語音識別技術(shù)主要有動態(tài)時間規(guī)整技術(shù)(DTW)、隱馬爾可夫模型(HMM)、矢量量化(VQ)、人工神經(jīng)網(wǎng)絡(luò)(ANN)、支持向量機(SVM)等技術(shù)方法。
動態(tài)時間規(guī)整算法(DynamicTime Warping,DTW)
是在非特定人語音識別中一種簡單有效的方法,該算法基于動態(tài)規(guī)劃的思想,解決了發(fā)音長短不一的模板匹配問題,是語音識別技術(shù)中出現(xiàn)較早、較常用的一種算法。在應(yīng)用DTW算法進行語音識別時,就是將已經(jīng)預(yù)處理和分幀過的語音測試信號和參考語音模板進行比較以獲取他們之間的相似度,按照某種距離測度得出兩模板間的相似程度并選擇最佳路徑。
隱馬爾可夫模型(HMM)
是語音信號處理中的一種統(tǒng)計模型,是由Markov鏈演變來的,所以它是基于參數(shù)模型的統(tǒng)計識別方法。由于其模式庫是通過反復(fù)訓(xùn)練形成的與訓(xùn)練輸出信號吻合概率最大的最佳模型參數(shù)而不是預(yù)先儲存好的模式樣本,且其識別過程中運用待識別語音序列與HMM參數(shù)之間的似然概率達(dá)到最大值所對應(yīng)的最佳狀態(tài)序列作為識別輸出,因此是較理想的語音識別模型。
矢量量化(VectorQuantization)
是一種重要的信號壓縮方法。與HMM相比,矢量量化主要適用于小詞匯量、孤立詞的語音識別中。其過程是將若干個語音信號波形或特征參數(shù)的標(biāo)量數(shù)據(jù)組成一個矢量在多維空間進行整體量化。把矢量空間分成若干個小區(qū)域,每個小區(qū)域?qū)ふ乙粋€代表矢量,量化時落入小區(qū)域的矢量就用這個代表矢量代替。矢量量化器的設(shè)計就是從大量信號樣本中訓(xùn)練出好的碼書,從實際效果出發(fā)尋找到好的失真測度定義公式,設(shè)計出最佳的矢量量化系統(tǒng),用最少的搜索和計算失真的運算量實現(xiàn)最大可能的平均信噪比。
在實際的應(yīng)用過程中,人們還研究了多種降低復(fù)雜度的方法,包括無記憶的矢量量化、有記憶的矢量量化和模糊矢量量化方法。
人工神經(jīng)網(wǎng)絡(luò)(ANN)
是20世紀(jì)80年代末期提出的一種新的語音識別方法。其本質(zhì)上是一個自適應(yīng)非線性動力學(xué)系統(tǒng),模擬了人類神經(jīng)活動的原理,具有自適應(yīng)性、并行性、魯棒性、容錯性和學(xué)習(xí)特性,其強大的分類能力和輸入—輸出映射能力在語音識別中都很有吸引力。其方法是模擬人腦思維機制的工程模型,它與HMM正好相反,其分類決策能力和對不確定信息的描述能力得到舉世公認(rèn),但它對動態(tài)時間信號的描述能力尚不盡如人意,通常MLP分類器只能解決靜態(tài)模式分類問題,并不涉及時間序列的處理。盡管學(xué)者們提出了許多含反饋的結(jié)構(gòu),但它們?nèi)圆蛔阋钥坍嬛T如語音信號這種時間序列的動態(tài)特性。由于ANN不能很好地描述語音信號的時間動態(tài)特性,所以常把ANN與傳統(tǒng)識別方法結(jié)合,分別利用各自優(yōu)點來進行語音識別而克服HMM和ANN各自的缺點。
近年來結(jié)合神經(jīng)網(wǎng)絡(luò)和隱含馬爾可夫模型的識別算法研究取得了顯著進展,其識別率已經(jīng)接近隱含馬爾可夫模型的識別系統(tǒng),進一步提高了語音識別的魯棒性和準(zhǔn)確率。
支持向量機(Supportvector machine)
是應(yīng)用統(tǒng)計學(xué)理論的一種新的學(xué)習(xí)機模型,采用結(jié)構(gòu)風(fēng)險最小化原理(Structural Risk Minimization,SRM),有效克服了傳統(tǒng)經(jīng)驗風(fēng)險最小化方法的缺點。兼顧訓(xùn)練誤差和泛化能力,在解決小樣本、非線性及高維模式識別方面有許多優(yōu)越的性能,已經(jīng)被廣泛地應(yīng)用到模式識別領(lǐng)域。
語音識別技術(shù)的難點及對策
語音識別技術(shù)的發(fā)展,達(dá)不到實用要求的,主要表現(xiàn)在以下方面 :
(1) 自適應(yīng)問題 。
語音識別系統(tǒng)的自適應(yīng)性差體現(xiàn)在對環(huán)境條件的依賴性強。 現(xiàn)有倒譜歸一化技術(shù)、相對譜(RASTA)技術(shù)、LINLOG RASTA 技術(shù)等自適應(yīng)訓(xùn)練方法。
(2)噪聲問題。
語音識別系統(tǒng)在噪聲環(huán)境下使用,講話人產(chǎn)生情緒或心里上的變化 ,導(dǎo)致發(fā)音失真、發(fā)音速度和音調(diào)改變 ,產(chǎn)生Lombard/Loud 效應(yīng)。 常用的抑制噪聲的方法有譜減法、環(huán)境規(guī)正技術(shù)、不修正語音信號而是修正識別器模型使之適合噪聲、建立噪聲模型。
(3)語音識別基元的選取問題 。
一般地,欲識別的詞匯量越多,所用基元應(yīng)越小越好。
(4 )端點檢測。
語音信號的端點檢測是語音識別的關(guān)鍵第一步。研究表明,即使在安靜的環(huán)境下,語音識別系統(tǒng)一半以上的識別錯誤來自端點檢測器。提高端點檢測技術(shù)的關(guān)鍵在于尋找穩(wěn)定的語音參數(shù) 。
(5 )其它如識別速度問題 、拒識問題以及關(guān)鍵詞檢測技術(shù)(即從連續(xù)語音中去除 “啊”、“唉”的語氣助詞,獲得真正待識別的語音部分 )、對用戶的錯誤輸入不能正確響應(yīng)等問題 。
語音識別的應(yīng)用
語音識別可以應(yīng)用的領(lǐng)域大致分為大五類:
辦公室或商務(wù)系統(tǒng)。典型的應(yīng)用包括:填寫數(shù)據(jù)表格、數(shù)據(jù)庫管理和控制、鍵盤功能增強等等。
制造業(yè)。
在質(zhì)量控制中,語音識別系統(tǒng)可以為制造過程提供一種“不用手”、“不用眼”的檢控(部件檢查)。
電信。
相當(dāng)廣泛的一類應(yīng)用在撥號電話系統(tǒng)上都是可行的,包括話務(wù)員協(xié)助服務(wù)的自動化、國際國內(nèi)遠(yuǎn)程電子商務(wù)、語音呼叫分配、語音撥號、分類訂貨。
醫(yī)療。
這方面的主要應(yīng)用是由聲音來生成和編輯專業(yè)的醫(yī)療報告。
其他。
包括由語音控制和操作的游戲和玩具、幫助殘疾人的語音識別系統(tǒng)、車輛行駛中一些非關(guān)鍵功能的語音控制,如車載交通路況控制系統(tǒng)、音響系統(tǒng)。
隨著移動互聯(lián)網(wǎng)技術(shù)的不斷發(fā)展,尤其是移動終端的小型化、多樣化變化趨勢,語音識別成為區(qū)別于鍵盤、觸屏的人機交互手段之一。隨著語音識別算法模型、自適應(yīng)性的加強,相信在未來很長一段時間內(nèi),語音識別系統(tǒng)的應(yīng)用將更加廣泛與深入,更多豐富的移動終端語音識別產(chǎn)品將步入人們的日常生活。
推薦閱讀:
如何克服功率計等測量儀器測試的不穩(wěn)定?
如何準(zhǔn)確識別未知多節(jié)點CAN總線網(wǎng)絡(luò)?
全面概括汽車傳感器知識
靈感來源于電鰻的柔性電池:未來或許能為起搏器供電
VR并沒有沒落 去年它在這些方面改變了世界
推薦閱讀:
如何克服功率計等測量儀器測試的不穩(wěn)定?
如何準(zhǔn)確識別未知多節(jié)點CAN總線網(wǎng)絡(luò)?
全面概括汽車傳感器知識
靈感來源于電鰻的柔性電池:未來或許能為起搏器供電
VR并沒有沒落 去年它在這些方面改變了世界
